[PS] BOJ 1717 / 집합의 표현

![[PS] BOJ 1717 / 집합의 표현](/content/images/size/w2000/2025/07/------1--4.png)
문제 링크: https://www.acmicpc.net/problem/1717
Thumbnail: Photo by Orevaoghene Ahia (Unsplash)
분리 집합을 구현하는 방법인 Union-Find 알고리즘을 구현하는 문제입니다.
풀이
분리 집합(Disjoint Set)?
분리 집합의 수학적 정의는 다음과 같습니다:
전체 집합 \(U\)에 대해, 서로 겹치는 원소를 가지지 않는 둘 이상의 부분 집합 \(A, B\)를 말합니다. 두 개의 부분 집합으로 나눌 때, 조건은 다음과 같습니다.
- \(A \subset U\), \(B \subset U\)
- \(A \cap B = \O\)
- \(A \cup B = U\)
Union-Find?
Union-Find 알고리즘은 분리 집합 자료구조를 구현하기 위해 사용하는 방법입니다.
Union-Find 알고리즘은 2가지 연산을 구현합니다.
- find_parent(x) : 임의의 원소 \(x\)가 속한 집합을 구합니다.
- union(x, y) : 두 원소 \(x, y\)가 속한 두 부분 집합을 병합합니다.
# Union-Find
parents = [i for i in range(N + 1)] # 1부터 N까지의 각 원소에 대해 자신이 속한 집합의 대표 원소를 저장하는 배열
def find_parent(x):
"""임의의 원소 x가 속한 부분 집합을 구합니다.
반환되는 정수 값은 x가 속한 부분 집합의 루트 노드입니다."""
while x != parents[x]:
path.append(x)
x = parents[x]
return x
def union(x, y):
"""두 원소 x, y가 속한 두 부분 집합을 병합합니다."""
parent_x = find_parent(x)
parent_y = find_parent(y)
if parent_x != parent_y:
parents[parent_y] = parent_xUnion-Find 알고리즘의 구현
Union-Find 알고리즘 최적화
위 Union-Find 알고리즘의 구현을 보면, 매번 union 연산을 수행할 때마다 한쪽 부분 집합의 루트 노드가 다른 쪽 부분 집합의 자식 노드로 포함되게 됩니다.
이런 방식으로는 입력 데이터에 따라 집합을 저장하는 트리가 한쪽 방향으로 깊게 늘어질 수 있으며, 이런 상태에서는 find_parent(x)에서 반복하는 횟수가 증가해 전체적인 계산 시간이 느려집니다.
이 문제는 Union-Find의 구현을 개선해서 예방할 수 있습니다.
1) find_root(x) 최적화: 경로 압축(Path Compression)
매번 find_root(x)를 진행할 때 마다, 자식 노드부터 루트 노드까지 반복해서 거슬러 올라가는 과정은 불필요합니다. 한 번 거슬러 올라간 뒤, 방문했던 모든 노드들의 부모 노드를 바로 루트 노드로 변경한다면, 다음 번 find_root(x)는 1회 탐색만으로 답을 찾아낼 수 있습니다.
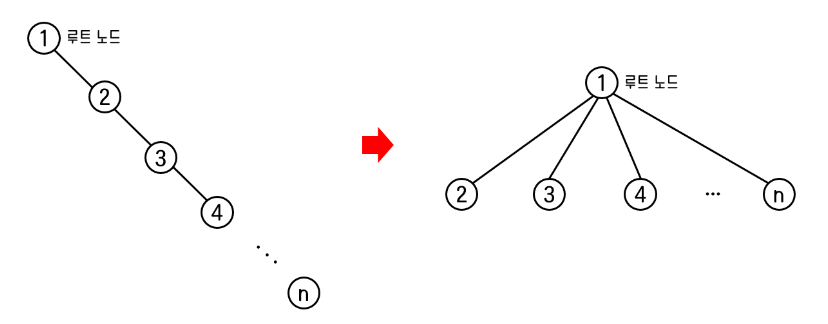
이미지 출처: Union-Find 최적화
# 재귀 구현
def find_parent(x):
if x == parents[x]:
return x
parents[x] = find_parent(parents[x])
return parents[x]
# 반복문 구현
def find_parent(x):
path = []
while x != parents[x]:
path.append(x)
x = parents[x]
for p in path:
parents[p] = x
return xPath Compression 구현
2) union(x, y) 최적화: Union by Rank
기존 union(x, y)연산은 항상 x가 속한 집합(집합 B)에 y가 속한 집합(집합 A)을 하위 노드로 추가하고 있습니다.
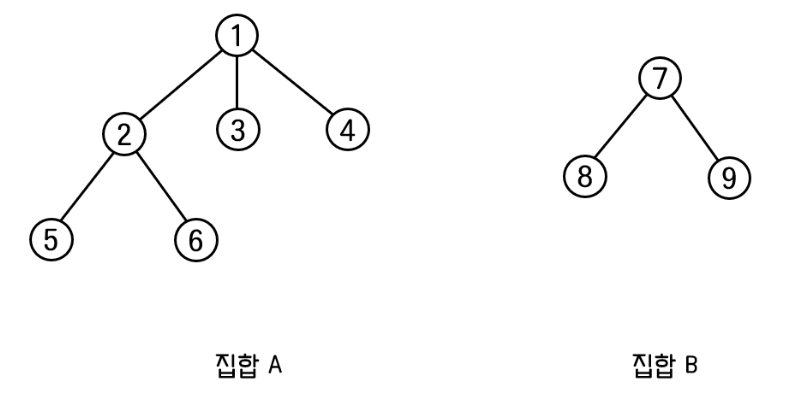
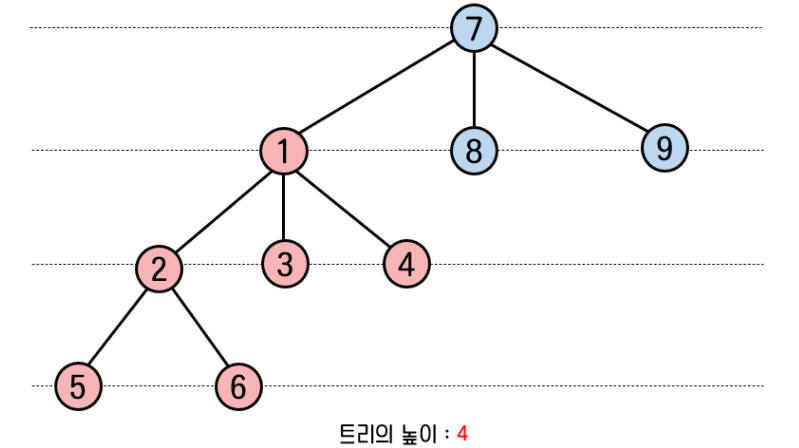
만약 집합 A의 트리의 높이(rank)가 더 크다면, 반대로 집합 B를 집합 A의 하위 노드로 추가하는 편이 탐색 시간을 줄여 전체 성능에 유리합니다.
# Union-Find
parents = [i for i in range(N + 1)] # 1부터 N까지의 각 원소에 대해 자신이 속한 집합의 대표 원소를 저장하는 배열
ranks = [0 for _ in range(N + 1)] # 각 원소가 속한 집합의 트리의 높이를 저장할 배열
def find_parent(x):
... # 기존과 동일
def union(x, y):
"""두 원소 x, y가 속한 두 부분 집합을 병합합니다."""
parent_x = find_parent(x)
parent_y = find_parent(y)
if parent_x == parent_y: # 이미 x와 y가 같은 집합에 속해 있다면 합치지 않는다.
return
# 항상 높이가 더 낮은 트리를 높이가 높은 트리 밑에 넣는다.
# 즉, 높이가 더 높은 쪽을 root로 삼음
if ranks[parent_x] < ranks[parent_y]:
parents[parent_x] = parent_y
else:
parents[parent_y] = parent_x
if ranks[parent_x] == ranks[parent_y]:
ranks[parent_x] += 1 # 만약 높이가 같다면 합친 후 (x의 높이 + 1)Union by Rank 구현
전체 코드
input = open(0).readline
N, M = map(int, input().split())
# Union-Find
parents = [i for i in range(N + 1)]
ranks = [0 for _ in range(N + 1)] # 각 원소가 속한 집합의 트리의 높이를 저장할 배열
def find_parent(x):
path = []
while x != parents[x]:
path.append(x)
x = parents[x]
for p in path:
parents[p] = x
return x
def union(x, y):
"""두 원소 x, y가 속한 두 부분 집합을 병합합니다."""
parent_x = find_parent(x)
parent_y = find_parent(y)
if parent_x == parent_y: # 이미 x와 y가 같은 집합에 속해 있다면 합치지 않는다.
return
# 항상 높이가 더 낮은 트리를 높이가 높은 트리 밑에 넣는다.
# 즉, 높이가 더 높은 쪽을 root로 삼음
if ranks[parent_x] < ranks[parent_y]:
parents[parent_x] = parent_y
else:
parents[parent_y] = parent_x
if ranks[parent_x] == ranks[parent_y]:
ranks[parent_x] += 1 # 만약 높이가 같다면 합친 후 (x의 높이 + 1)
for _ in range(M):
cmd, a, b = map(int, input().split())
if cmd == 0:
union(a, b)
else:
print("YES" if find_parent(a) == find_parent(b) else "NO")
solution.py